For more details, visits the project website & Github Repo
Updates
v2.1 (03/04/2019)
Updated chart view: now you can choose the data you want to make a chart for it
v2.0 (02/26/2019)
New GUI design
Add menu for multiple planes data access
Two view modes: the table view and the chart view
Real-time data updating and parsing
Rawdata file can be download directly
v1.1 (12/08/2018)
Bug Fix: Fix the csrf verification issue when user click on the return key.
v1.0 (12/07/2018)
Release for tech demo
Finished the implementation of Django, include the user authencation, database connection and data integrity verification by hash value
Description

![]()
Honeywell Aerospace is a leading manufacturer of all sorts of aircraft engines ranging from helicopters to commercial airliners. These engines and their connected systems generate data every flight that is important for the functionality of their product. While in flight, an engine is constantly reading sensor data and storing it on the onboard computer called the Engine Control Unit (ECU). Currently, to gather this data, a technician will physically download the data from the ECU through a wire connection. The cumbersome process of physically connecting to a computer and downloading this data on location greatly limits the amount of flight data to collect.
Our team, TLD Worker Bee, are working on the project Prototype Time Limited Dispatch (TLD) Application for our sponsor, Harlan Mitchell from Honeywell Aerospace. The initial concept for this project was provided by our sponsor, in the form of a Capstone project proposal. Our prototype is a web app that uses an internet connection to connect to the data stored in the cloud for a completely wireless experience. It verifies data integrity before showing the user any data to avoid reading false data. This ensures the mechanic knows exactly what maintenance to perform on the engine from anywhere in the world.
Requirements
For our requirements acquisition process, we began by brainstorming different use cases for our product to see how a typical user might interact with our system. We were able to come up with a few requirements of our own, but we wanted our sponsor’s opinion on what requirements he felt our system should have as well. We spoke to our sponsor, Harlan Mitchell, about what he would like to see in our final product and how he would like the final product to perform. We explained to him our proposed solution and what we had in mind to fix his problem, and he explained how our proposed solution needs to perform. From this discussion, we gathered a handful of functional and non-functional requirements.
Our functional requirements are as follows:
[F-SYS1] The web viewer tool shall download the raw data file from the cloud to the user’s computer upon user’s request.
[F-SYS2] The web viewer tool shall display the data stored in the database.
[F-GUI1] The user shall navigate to data by plane tail number.
[F-GUI2] The GUI shall be adaptive for PCs and tablets using Google Chrome.
Note: Adaptive means the user will see the data without needing to side scroll.
These functional requirements describe how the system is expected to function; they cover both system requirements and GUI requirements.
Our non-functional or performance requirements are as follows:
- [P-GUI3] The web viewer tool shall display data onto the web page after receiving it from the cloud.
- [P-DT1] The database shall reject SQL injection 100% of the time.
- [P-SYS3] The web viewer tool shall explicitly validate the data after receiving it from the cloud before displaying it on the web browser. This validation will be done by comparing local and cloud MD5 hash values for the data.
These non-functional requirements describe benchmark goals for the system; they cover system, GUI, and database requirements.
Solution
The solution our team has in mind to build for our sponsor is a prototype web application that will serve as a viewing tool for data that is stored in a cloud. The web application will be able to download the data files a user is requesting from the cloud and display them in the web browser of choice. The web viewing tool we build will be usable on Google Chrome and Apple Safari.
We have three main components that will each serve a purpose in our solution: cloud storage, parsing and verification services, and a web application. The cloud storage contains the databases for this prototype: one to store data for processing and one to store data that is already processed. These databases communicate with each other using Python to perform operations on the pre-processed data. We will be using Amazon S3 cloud storage to hold the database containing the pre-processed data and Amazon RDS to hold the database containing the processed data. The RDS database is the one that will be accessed when a user makes a data request in the web application. Before the data reaches the web application, it will be sent through a parsing and a verification tool. These tools/services will ensure data integrity throughout the data flow process. For the web application itself, we will be using Django and Python to create a web page to display data that a user requests from the database. This flow of data can be seen below in figure 1.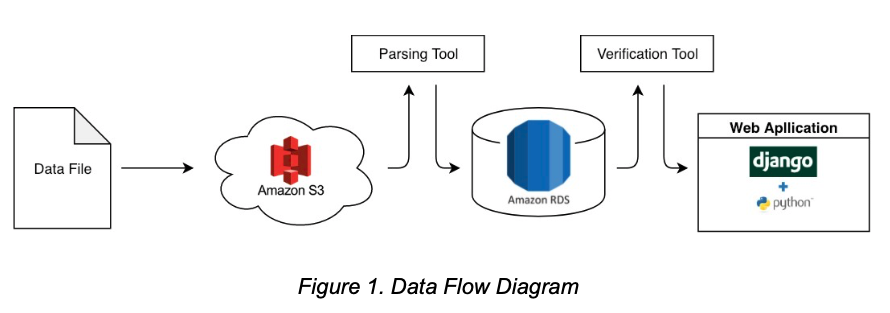
The data starts by being collected from the ECU and is then sent to the Amazon S3 cloud database. From there, the data is sent through a parsing tool for data processing and is then sent to the Amazon RDS database. Once the user makes a request for data, it is passed through a verification tool before it is displayed to the user in the web application.
The components discussed above will be used to create software that adheres to the Model View Presenter (MVP) model, a key part of which is that data is handled and represented in three separate layers. These layers are as follows:
- Database Layer: where the data used by the software is stored(Model)
- Presentation Layer: where the data used by the software is displayed(View)
- Service Layer: where the data used by the software is parsed and verified.(Presenter)
This separation of responsibilities surrounding the data into separate layers ensures a level of security with data parsing and makes sure that the data that is displayed is accurate. This configuration is shown in figure 2.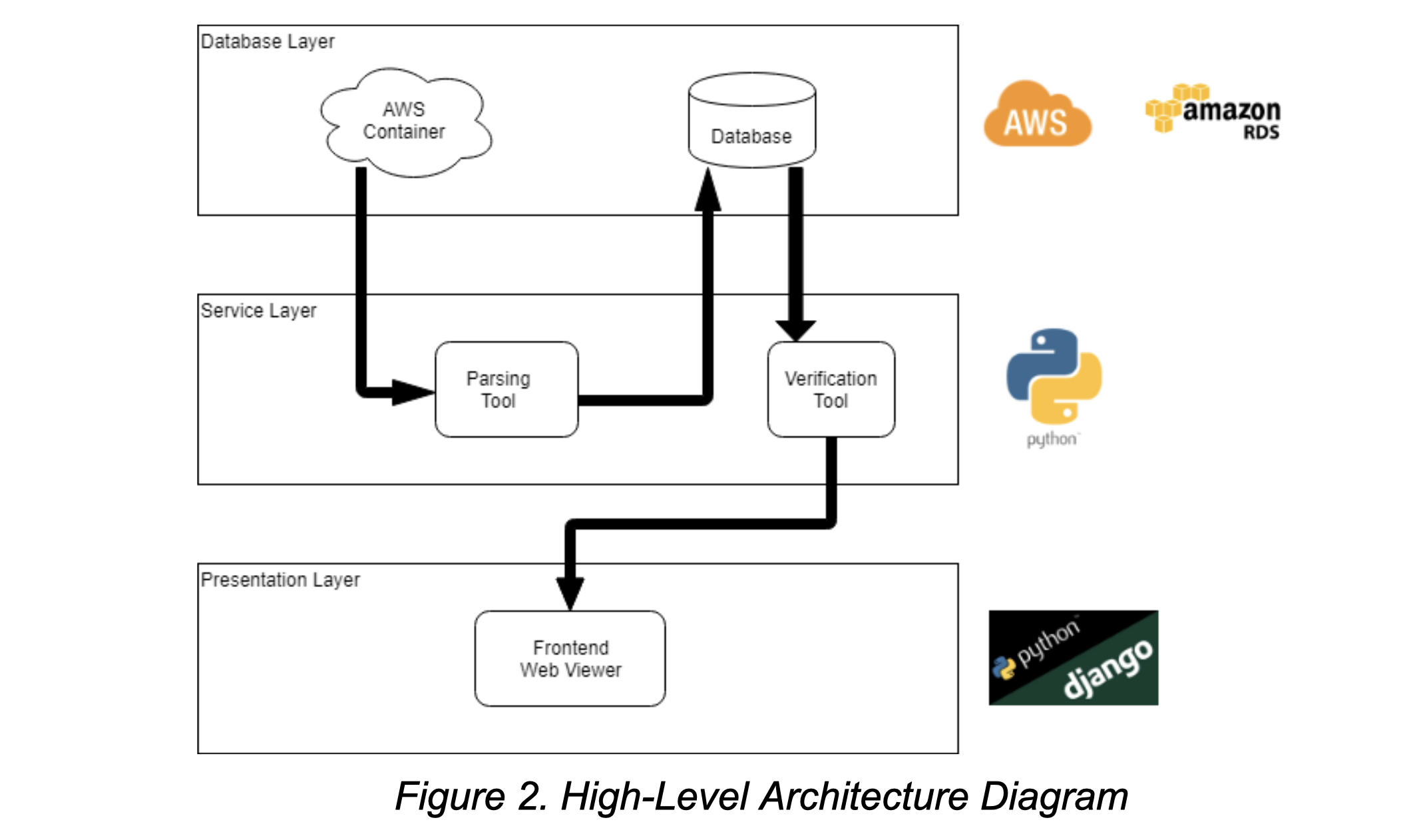
Here are two data view modes to display the TLD data:
Table View
The table view mode is able to provide an organized way to arrange and display the TLD data by using easy-to-read table and grid structure.
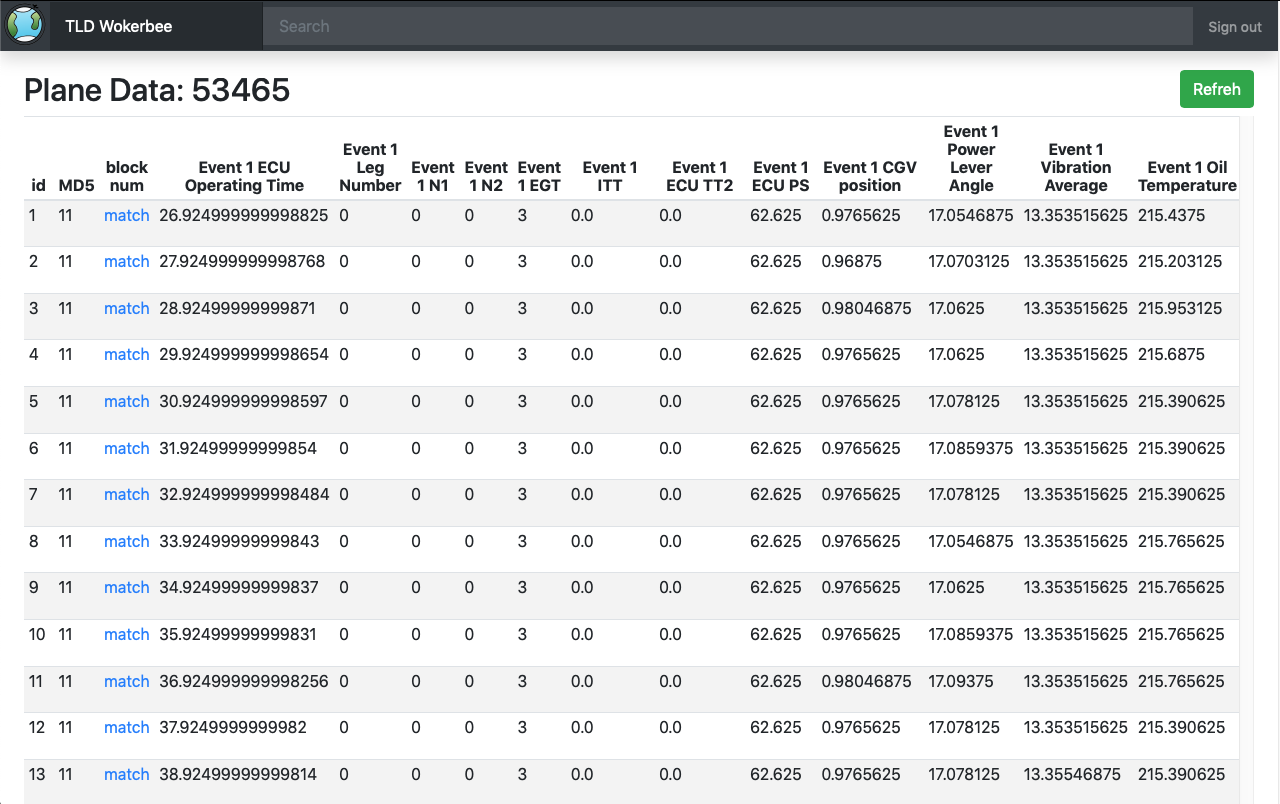
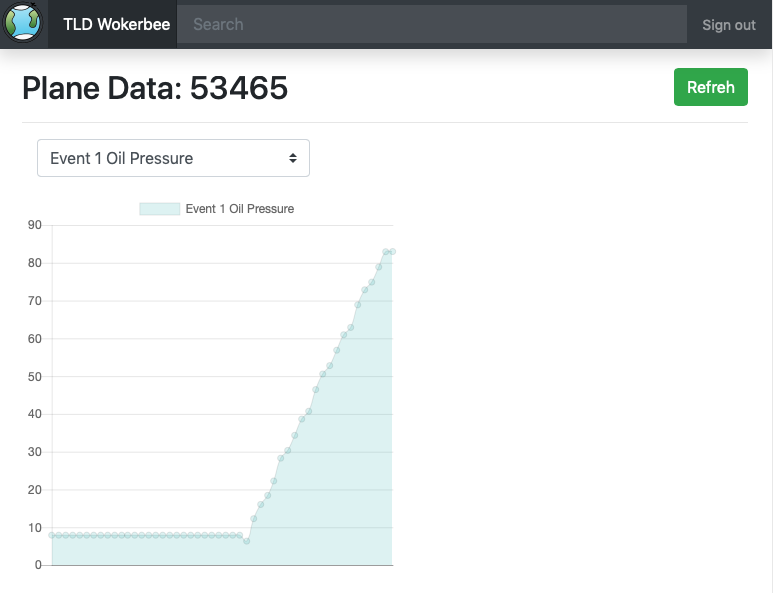
Chart View
The chart view mode allows the user to plot the specific TLD data, and generate the line chart of that data to help the user analyze the properties and tendency of the specific TLD data.
Technology
Here are some technologies and services we choose for this project:
Python Environment
- Python 3.6 (Python is an interpreted, high-level, general-purpose programming language. All the program and components of this project is written in Python)
- Django 2.2.1 (Django is a high-level Python Web framework. This is the basic of the web application.) - Pip (Package manager for Python. Use it to install other python components or libraries like Virtualenv, awsebcli and Urllib3)
- Virtualenv (Python Virtual Environment. By using a virtual environment, you can discern exactly which packages are needed by your application so that the required packages are installed on the AWS instances that are running your application.)
- Awsebcli (Elastic Beanstalk Command Line Interface (EB CLI). This is used to initialize your application with the files necessary for deploying with Elastic Beanstalk.)
- Urllib3 (urllib3 is a powerful, sanity-friendly HTTP client for Python. We use it to transfer the raw TLD data from the cloud to the local environment)
Cloud & Database Services
- Amazon AWS S3 (Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. This is the simulated cloud environment for this project.)
- Amazon RDS (Amazon RDS is easy to set up, operate, and scale a relational database in the cloud.)- Amazon Elastic Beanstalk (AWS Elastic Beanstalk is an easy-to-use service for deploying and scaling web applications and services developed with Java, .NET, PHP, Node.js, Python, Ruby, Go, and Docker on familiar servers such as Apache, Nginx, Passenger, and IIS.)
- MySQL 5.1 (MySQL is a relational database management system. We use MySQL to manage the database)- Sequel Pro (Sequel Pro is a fast, easy-to-use Mac database management application for working with MySQL databases.)
- MySQL Workbench (MySQL Workbench is a visual database design tool)
Code Editor & IDE
- Sublime Text 3 (Sublime Text is a proprietary cross-platform source code editor with a Python API. It’s easy to develop code with Sublime Text 3)
- vim (Vim is a highly configurable text editor built to enable efficient text editing.)

